

Building a Salesforce Extraction Pipeline from Scratch: Part 2 — Fetching Data with the REST API
Introduction
Welcome back to the second installment of our series on building a Salesforce extraction pipeline from scratch, without relying on special libraries or SaaS services. In the first part, we covered how to authenticate with Salesforce using the SOAP API. Now that we can securely connect to Salesforce, it’s time to fetch some data!
In this article, we’ll focus on retrieving records from Salesforce using the REST API. We’ll delve into query generation, handling fields, and dealing with Salesforce’s pagination structure. A key aspect we’ll explore is how to manage field selections in SOQL queries, especially considering the limitations around unbounded queries and the use of FIELDS(ALL). By the end of this article, you’ll be able to extract data efficiently and prepare it for further processing or storage.
As before, all the code discussed here is available in the GitHub repository for this series. Each part of the series has its own branch, with each successive branch building upon the previous one.
You can find the repository here:
Understanding the Salesforce REST API
The Salesforce REST API provides a powerful, convenient, and simple Web services interface for interacting with Salesforce. It allows you to perform various operations such as querying data, updating records, and accessing metadata.
One of the key features we’ll utilize is the ability to execute SOQL (Salesforce Object Query Language) queries via the REST API. SOQL is similar to SQL but is designed specifically for Salesforce data structures.
Retrieving Records: The salesforce_rest_api.py Module
Let’s dive into the salesforce_rest_api.py module, which handles querying Salesforce data using the REST API.
Imports and Dependencies
import requests
import os
from salesforce_authentication import get_session_id
from helper_functions import get_credentials, get_nested_values
- requests: Used for making HTTP requests to the Salesforce REST API.
- os: Used to access environment variables.
- salesforce_authentication.get_session_id: Reuses the authentication function we created in Part 1 to obtain a session ID.
- helper_functions.get_credentials: Retrieves stored Salesforce credentials.
- helper_functions.get_nested_values: A utility function to extract values from nested data structures.
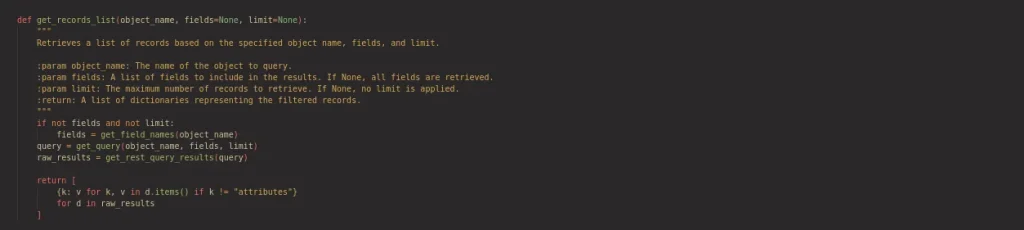
Main Function: get_records_list
def get_records_list(object_name, fields=None, limit=None):
"""
Retrieves a list of records based on the specified object name, fields, and limit.:param object_name: The name of the object to query.
:param fields: A list of fields to include in the results. If None, all fields are retrieved.
:param limit: The maximum number of records to retrieve. If None, no limit is applied.
:return: A list of dictionaries representing the filtered records.
"""
if not fields and not limit:
fields = get_field_names(object_name)
query = get_query(object_name, fields, limit)
raw_results = get_rest_query_results(query)
return [
{k: v for k, v in record.items() if k != "attributes"}
for record in raw_results
]
This is the primary function you’ll use to retrieve records:
Parameters:
- object_name: The Salesforce object you want to query (e.g., Account, Contact).
- fields: A list of specific fields to retrieve. If None, all fields are retrieved.
- limit: The maximum number of records to return. If None, all records are retrieved.
Process:
- Checks if both fields and limit are None. If so, it fetches all field names for the object using get_field_names.
- Constructs a SOQL query using get_query.
- Executes the query using get_rest_query_results.
- Cleans up the results by removing the attributes metadata from each record.
Handling Fields in SOQL Queries
Before we delve into the helper functions, it’s important to understand how the fields parameter is handled and why.
The Challenge with FIELDS(ALL) and Unbounded Queries
In SOQL, you might be tempted to use SELECT FIELDS(ALL) FROM ObjectName to retrieve all fields, similar to SELECT * in SQL. However, Salesforce imposes limitations on the use of FIELDS(ALL):
- Unbounded Queries: When you do not specify a LIMIT clause, the query is considered unbounded.
- Restriction: Salesforce does not allow the use of FIELDS(ALL) in unbounded queries. This is to prevent performance issues that could arise from retrieving all fields for a large number of records.
Therefore, if you want to fetch all fields without specifying a limit, you cannot use FIELDS(ALL). Instead, you must explicitly list all field names in the SELECT clause.
Our Solution
To handle this, our get_records_list function checks if both fields and limit are None. If so, it proceeds to fetch all field names for the specified object using the get_field_names function. This list of field names is then used to construct the SOQL query.
By explicitly listing all field names, we comply with Salesforce’s requirements and avoid the limitations associated with FIELDS(ALL) in unbounded queries.
Helper Functions
Let’s explore the helper functions used within get_records_list.
Constructing the SOQL Query: get_query
def get_rest_query_results(query, next_url=None):
"""
Executes a REST API GET request to Salesforce with the given query.
Handles pagination recursively by checking for 'nextRecordsUrl' in the response.:param query: The SOQL query string to execute.
:param next_url: The nextRecordsUrl for pagination (used internally during recursion).
:return: A list of all records retrieved from Salesforce.
:raises Exception: If the REST query fails with a non-200 status code.
"""
if next_url is None:
url = f"{os.environ['SALESFORCE_URL']}/services/data/v60.0/{query}"
else:
url = f"{os.environ['SALESFORCE_URL']}{next_url}"
response = requests.get(
url,
headers={
"Authorization": f"Bearer {fetch_session_id()}",
"Content-Type": "application/json"
}
)
if response.status_code != 200:
raise Exception(f"REST query failed with a status of {response.status_code}: {response.text}")
data = response.json()
records = data.get("records", [])
# Recursively fetch more records if 'nextRecordsUrl' is present
if "nextRecordsUrl" in data:
next_records = get_rest_query_results(
query, next_url=data['nextRecordsUrl'])
records.extend(next_records)
return records
Purpose:
- Sends the SOQL query to Salesforce and retrieves the results.
Highlights:
- Handles pagination by checking for the nextRecordsUrl in the response and recursively fetching additional records.
- Uses the fetch_session_id function to obtain the session ID for authentication.
- Parses the JSON response and extracts the records.
Fetching All Field Names: get_field_names
def get_field_names(object_name):
"""
Retrieves all field names for the specified Salesforce object.:param object_name: The name of the Salesforce object to describe.
:return: A list of field names for the object.
:raises Exception: If the field name query fails with a non-200 status code.
"""
response = requests.get(
f"{os.environ['SALESFORCE_URL']}/services/data/v60.0/sobjects/{object_name}/describe/",
headers={
"Authorization": f"Bearer {fetch_session_id()}"
}
)
if response.status_code != 200:
raise Exception(f"Field name query failed with a status of {response.status_code}: {response.text}")
return get_nested_values("name", response.json()["fields"])
Purpose:
- Retrieves all field names for a given object by calling the describe endpoint.
Why This Is Important:
- As discussed, when performing an unbounded query (without a LIMIT), you cannot use FIELDS(ALL).
- To retrieve all fields in such a case, you must explicitly list all field names in the SELECT clause.
Highlights:
- Makes a GET request to the describe endpoint for the specified object.
- Parses the response to extract field names using the get_nested_values utility function.
Fetching the Session ID: fetch_session_id
def fetch_session_id():
"""
Fetches the current Salesforce session ID using stored credentials.:return: The Salesforce session ID as a string.
"""
credentials = get_credentials("salesforce")
return get_session_id(
credentials["salesforce_username"],
credentials["salesforce_password"],
credentials["salesforce_security_token"]
)
Purpose:
- Obtains a session ID using the stored credentials, reusing the authentication function from Part 1.
Highlights:
- Retrieves credentials using get_credentials.
- Calls get_session_id to authenticate and obtain a session ID.
Utility Functions: helper_functions.py
The helper_functions.py module provides utility functions used by the main module.
Loading Environment Variables
import os
from dotenv import load_dotenv# Load variables from .env file
load_dotenv()
Purpose:
- Loads environment variables from a .env file, which is useful for local development without exposing sensitive information.
Retrieving Credentials: get_credentials
def get_credentials(integration):
return {
f"{integration}_password": os.environ[f"{integration.upper()}_PASSWORD"],
f"{integration}_username": os.environ[f"{integration.upper()}_USERNAME"],
f"{integration}_security_token": os.environ[f"{integration.upper()}_SECURITY_TOKEN"]
}
Purpose:
- Retrieves credentials from environment variables for a given integration (in this case, Salesforce).
Highlights:
- Uses the integration name to construct the keys for environment variables.
- Assumes that environment variables are named in the format INTEGRATION_USERNAME, INTEGRATION_PASSWORD, etc.
Extracting Nested Values: get_nested_values
def get_nested_values(key, data):
values = [item[key] for item in data]
return values
- Purpose: Extracts a list of values corresponding to a specified key from a list of dictionaries.
- Usage: Used to extract field names from the JSON response in get_field_names.
In Action
Let’s see how to use the get_records_list function to retrieve data from Salesforce.
Example: Fetch All Accounts
import salesforce_rest_api as sf_api
# Retrieve all accounts with all fields
accounts = sf_api.get_records_list("Account")
print(accounts)
Explanation:
- Since neither fields nor limit is provided, the function fetches all field names for the Account object.
- Constructs a SOQL query that explicitly lists all fields.
- Retrieves all records for the Account object.
Example: Fetch Contacts with Specific Fields and Limit
import salesforce_rest_api as sf_api
fields = ["FirstName", "LastName", "Email"]
contacts = sf_api.get_records_list("Contact", fields=fields, limit=100)
print(contacts)
Explanation:
- Specifies a list of fields to retrieve.
- Sets a limit of 100 records.
- Constructs a SOQL query using FIELDS(ALL) is not necessary here since we have specified fields.
Example: Attempting an Unbounded Query with FIELDS(ALL)
import salesforce_rest_api as sf_api
# This will raise an exception
accounts = sf_api.get_records_list("Account", fields=None, limit=None)
Explanation:
- Since both fields and limit are None, the function will attempt to fetch all field names and include them explicitly in the query.
- If get_field_names fails or is not called, using FIELDS(ALL) without a limit would raise an exception due to Salesforce’s limitations.
Handling Pagination
Salesforce may limit the number of records returned in a single response. If the result set is large, Salesforce provides a nextRecordsUrl in the response, which you can use to fetch the next batch of records.
Our get_rest_query_results function handles this by recursively checking for nextRecordsUrl and fetching additional records until all records are retrieved.
Conclusion
In this article, we’ve built upon our authentication foundation to retrieve data from Salesforce using the REST API. We’ve covered:
- Constructing SOQL Queries Dynamically:
- Handling the fields parameter carefully to comply with Salesforce’s limitations.
- Understanding why unbounded queries cannot use FIELDS(ALL) and how to work around this by explicitly listing all fields.
- Handling Fields Selection and Limitations:
- Using the get_field_names function to retrieve all field names when needed.
- Ensuring that our queries are efficient and compliant with Salesforce’s requirements.
- Dealing with Salesforce’s Pagination Mechanism:
- Implementing recursive calls to handle large datasets.
- Ensuring that all records are retrieved without manual intervention.
With these tools, you can now extract data from Salesforce efficiently and prepare it for storage, analysis, or further processing.
What’s Next
In the next article, we’ll delve into the Salesforce BULK API. We’ll explore how to handle large volumes of data extraction efficiently. The BULK API presents its own challenges, particularly around its asynchronous query system, where you have to wait and check on the query status before fetching results.
Stay tuned as we continue to build our stateless, distributed extraction pipeline, enhancing it to handle larger datasets and more complex scenarios. If you have any questions or need further clarification, feel free to leave a comment below.
I am open to consulting engagements if you need help building this or any other data solution. Feel free to email me directly at jason@hyperfocusdata.io