Introduction
When designing a data pipeline—or any project, for that matter—it’s best to build it as generalized or abstracted as possible. While an exception might be made if it’s intended only for a single, specific data source or target, things rarely remain static in the long run. A well-built pipeline will likely be used by multiple existing sources and almost certainly by new ones. Although this approach may involve a bit more time during the initial design or coding phase, it’s smart to invest that time upfront rather than deal with the technical debt of inadequate planning later on. In the following sections, I will discuss common methods and benefits of generalization, potential issues that might arise, and offer some concluding thoughts and advice on implementation.
Common Methods of Generalization
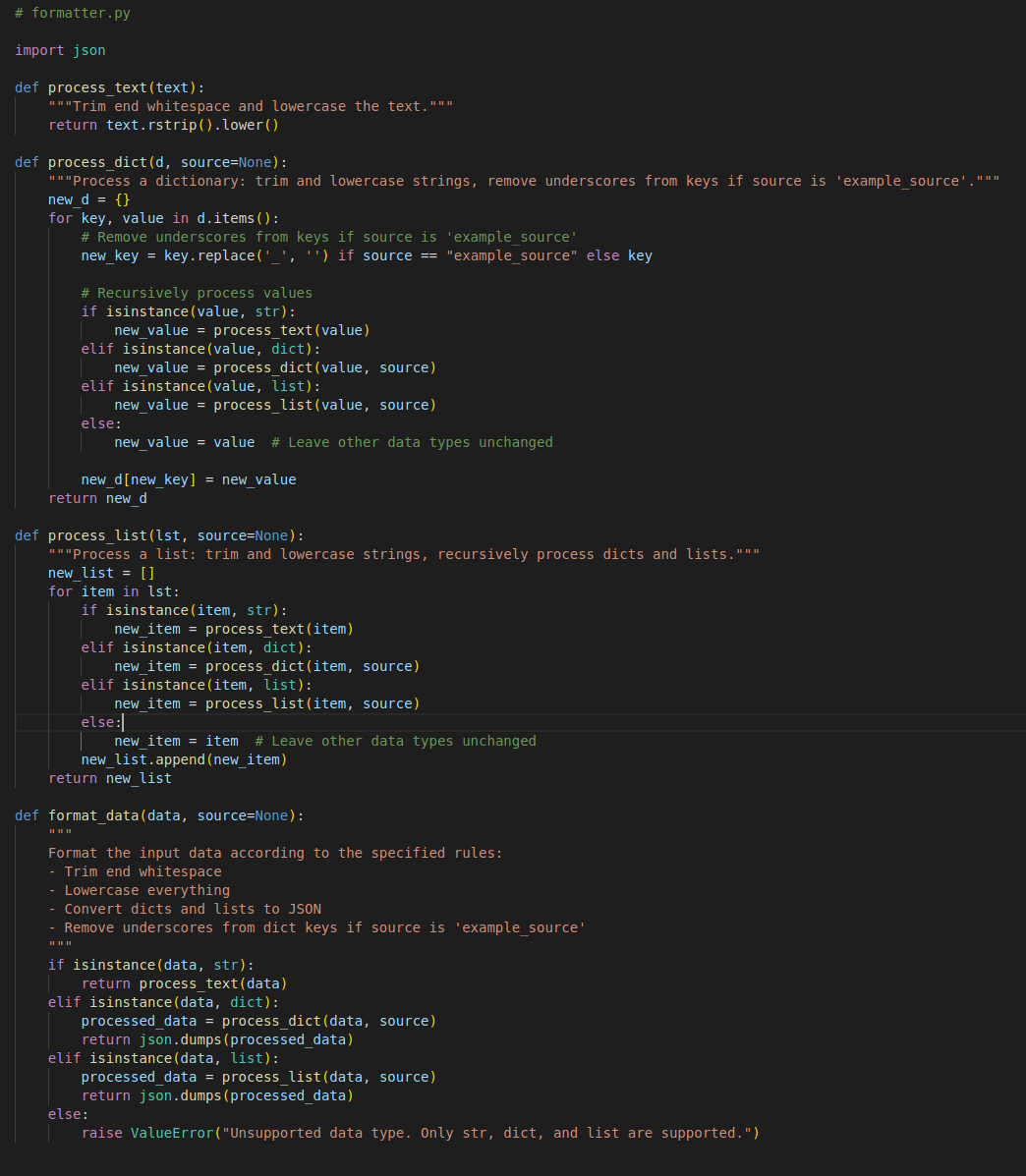
A common method of generalization is to follow the DRY (Don’t Repeat Yourself) principle by moving all common or repeated functions or code into separate modules or classes. For example, if you have multiple modules connecting to different data sources (and each formats incoming data into specific data types or schemas) it would be beneficial to consolidate all formatting logic into a single module. This way, if you need to adjust how your code handles capitalization or NULL values, you only have to change one function instead of updating multiple places. Admittedly, this approach requires some planning. The formatting for one source might interfere with another, but this issue can often be resolved through function overloading or using flag arguments. While it may initially add what feels like unnecessary planning time, it will save a significant amount of time when testing and adding or modifying data sources.
Here is an example of a simple `formatter` module (it is purposefully simple for illustration purposes), it can handle basic transformations for several sources, and has a flag to treat `example_source` slightly differently:
Building on the previous method, it’s advisable not to name functions or variables too specifically when generalizing. There’s often a tendency to assign a name to a function or variable that fits its initial use, but this can cause problems when you later abstract or generalize your codebase or pipeline. For instance, if you begin by extracting data from a single API—say, the Salesforce Bulk API—you might name the function that retrieves data something like `salesforce_bulk_api_results`. However, as you generalize this function to handle multiple APIs, such a specific name becomes misleading and may necessitate changes in several places within the codebase. The same applies to variable names within functions. If a generalized function still uses a specific name like `salesforce_api_results_dict`, it becomes harder to read and understand when used with other APIs.
Another highly beneficial method of generalization is the use of interfaces. In this context, interfaces involve moving all direct access to external systems into dedicated interface modules for each system. External systems include:
- databases
- shared APIs (those accessed by multiple modules)
- message brokers
For example, consider a [distributed pipeline that uses a message broker to pass jobs sequentially through the pipeline stages](https://medium.com/@jkimmerling/stateless-distributed-etl-pipelines-using-message-brokers-for-horizontal-scaling-96035f341899).
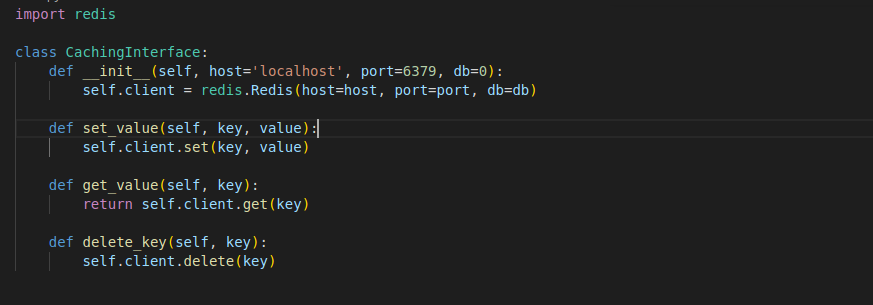
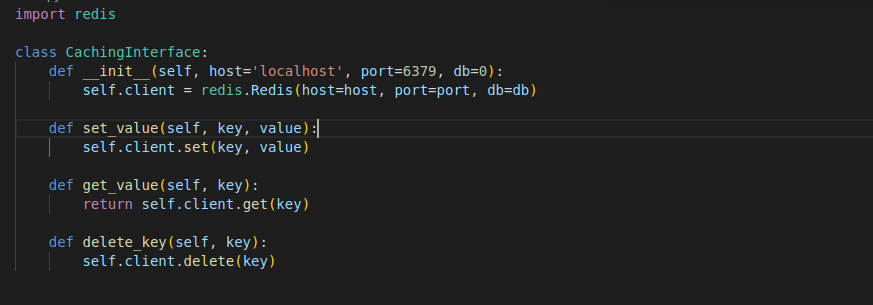
Without interface generalization, switching the message broker (e.g. from Kafka to Redis) requires modifications in multiple files throughout the pipeline. However, if you use an interface module to abstract access to the message broker, only the code within that module, which directly connects to the broker, needs to change. The internal access functions—the “interface”—remain the same, so other modules or parts of the pipeline remain unaffected. This makes the pipeline much more adaptable. Additionally, it helps avoid cloud vendor lock-in. If access to services like S3, Pub/Sub, or Cloud Composer is routed through their own interfaces, transitioning to a different cloud provider would require minimal re-coding, making such changes smoother and more cost-effective.
An example of a caching interface, currently using Redis:
This is the same interface, modified to use MongoDB instead:
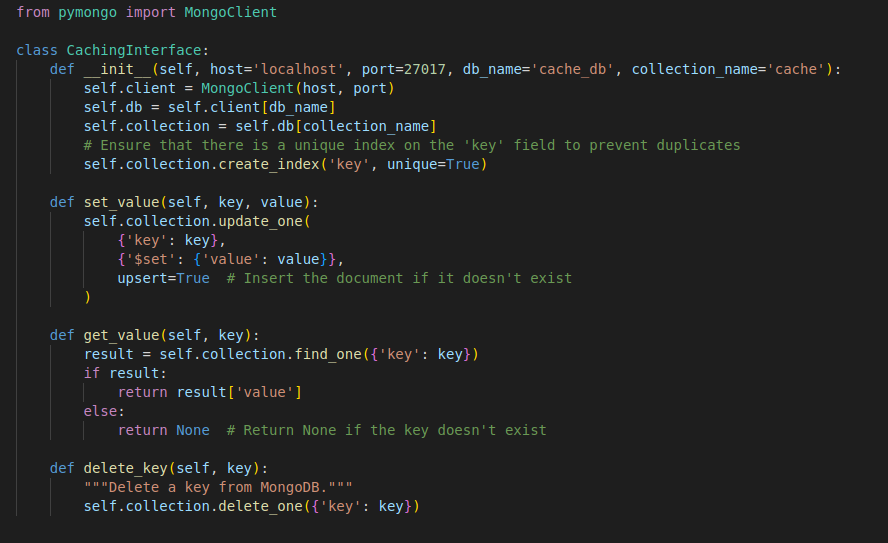
To the rest of the codebase nothing has changed. The class methods used to access the “cache” stay the same, so no other re-coding needs to be done.
The final method is equally important: moving configuration values or variables outside of the code itself. Configuration can be ambiguous, but here it refers to anything that might need to be changed or adjusted, such as delay timers, database IPs, bucket names, and so on. While you’ll need to decide what fits under this umbrella—and items can be added or removed over time—the key point is to extract them from the code. Having to redeploy a pipeline every time you want to adjust a delay timer is not only frustrating but also a significant waste of time and can risk causing outages, depending on the pipeline’s uptime requirements. Here are three ways it can be achieved:
- The simplest way to externalize configuration is to place all values in a flat file accessible by the running pipeline. This works but is clunky and requires direct access to the VM or container file system.
- A better approach is to use environment variables within the VM or container. While an improvement, this method isn’t ideal, especially if sensitive credentials are involved.
- In my experience, the optimal solution is a combination of methods. I prefer to store credentials in a secure service like AWS Secret Manager, place any configuration required to start the pipeline in environment variables, and keep the remaining configuration values in a database. This setup allows changes without redeploying the pipeline and makes it easy to implement an API for adjusting parameters like source tables to extract or the maximum number of workers for each extraction.
Potential Issues with Generalization
The issues surrounding generalization typically arise when it’s taken to an extreme. The deeper you delve into generalization, the more likely these issues are to appear.
The first problem which can arise with generalization is diminishing returns. Significant rewards can be reaped by implementing basic interfaces and consolidating repeated code into modules or functions, often with minimal effort for substantial rewards. However, after completing these initial generalizations, it’s prudent to pause and assess the effort versus the reward. If restructuring two dissimilar functions to extract partially repeated code requires substantial effort and adds complexity, it might be better to forgo that change.
Another dilemma is reduced code readability. This often occurs when someone new to generalization starts applying it excessively. The temptation to generalize everything can lead to splitting functions into too many small parts, making them little more than wrappers around built-in functions, or creating function names so generic that they fail to convey their true purpose.
Below is an example of going too far with function splitting:
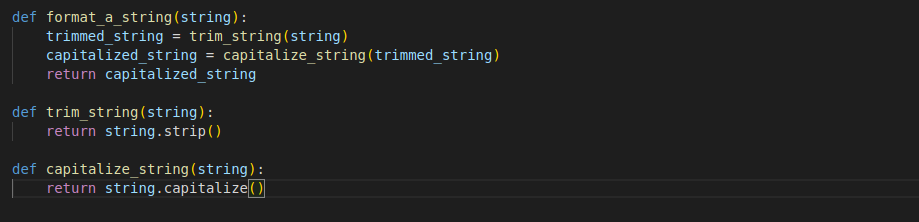
The creation of trim_string and `capitalize_string` provided no real benefit, and it would have been much better to use `.strip()` and `.capitalize()` in the `format_a_string` function.
Lastly, there’s the issue of justifying the time spent. While it might seem ideal to extract every possible benefit and make the code “perfect,” this consumes time and, consequently, money. If these efforts no longer contribute meaningfully to the bottom line, they become hard to justify. After making initial improvements to existing code or establishing basic abstractions in new code, it’s wise to evaluate the advantages of further generalization. If the cost outweighs the benefits, it’s best to move on.
Conclusion
In conclusion, the advantages of generalizing or abstracting your code when creating, designing, or maintaining a data pipeline or service are substantial. By investing a bit more time and effort upfront, you reap enormous benefits in the long run. The key to success is moderation. While generalization is highly advantageous, overdoing it can lead to excessive time spent on diminishing returns and may even introduce issues in future development. Overly abstracted code can become unreadable, confusing, or overly complex, posing challenges for new team members and ongoing maintenance.
I am open to consulting engagements if you need help building this or any other data solution. Feel free to email me directly at jason@hyperfocusdata.io