Introduction
Creating a stateless distributed ETL (Extract, Transform, Load) pipeline can be a daunting task, especially if you’re new to the concept. While there are many approaches to building such pipelines, one simple and effective method is to use message brokers. Tools like Kafka Streams, RabbitMQ, and even Redis Streams can simplify the process of constructing a stateless distributed pipeline.
The key to this setup is treating the message broker as a job or task server. In this article, I will illustrate this approach through an example scenario, explain how to achieve a stateless distributed pipeline, and provide advice on important features to consider when choosing a message broker.
Example Scenario
To demonstrate how message brokers can facilitate a distributed pipeline, let’s consider a practical example. This scenario is designed to illustrate the workflow when using a message broker as a distributed pipeline facilitator.
Imagine you’re tasked with extracting several Salesforce tables (objects) and storing the data in Snowflake for easy access by your Business Intelligence (BI) tools and Machine Learning (ML) pipelines. The pipeline needs to run multiple times a day, as tables like “ACCOUNT” update frequently.
General Flow
The general flow of the pipeline involves the following steps:
- Data Extraction: Use the Salesforce Bulk API to extract data, as you’re dealing with more rows than the REST API is recommended for. The data comes in as compressed CSV files.
- Data Storage: Send the CSV data to an Amazon S3 bucket.
- Data Loading: Perform a “MERGE INTO” operation for each target table in Snowflake to update or insert new records.
However, several factors could cause bottlenecks in this pipeline, such as variable extraction times due to differing table sizes, resource constraints with Snowflake, and high data volumes leading to slowdowns or “clogs.”
While vertical scalability (adding more resources to a single node) can address some issues, it has limits due to diminishing returns and increased costs. Therefore, incorporating horizontal scaling (adding more nodes) becomes essential. The challenge is to achieve this without adding complex clustering libraries or dealing with data duplication issues.
Leveraging Message Brokers for Horizontal Scaling
Message brokers provide an almost drop-in solution for smooth horizontal scaling without worrying about state management or data duplication. They are designed to handle the distribution of tasks and messages across multiple consumers efficiently.
By treating the message broker as a job server and keeping your task list and state in the form of messages in the queue, you can achieve a stateless distributed pipeline. Let’s explore how this works in the context of our example scenario.
Pipeline Setup
To address the challenges outlined earlier, we can set up the pipeline using three queues:
- Data Extraction Queue:
data_extraction_queue - S3 Upload Queue:
store_in_s3_queue - Snowflake Merge Queue:
merge_into_snowflake_queue
Pipeline Components
The pipeline consists of the following components:
1. Job Loader
- Function: Initializes the pipeline by sending messages to
data_extraction_queue. - Process:
- Creates a message for each Salesforce object/table that needs to be extracted.
- Each message contains information about the specific table/object, such as the object name and any parameters required for extraction.
- Sends these messages to
data_extraction_queue, effectively queuing up the extraction tasks.
2. Data Extraction Module
- Function: Processes extraction tasks from
data_extraction_queue. - Process:
- Subscription: Listens to
data_extraction_queue. - Task Execution:
- Retrieves a message containing details about a specific table/object to extract.
- Uses the Salesforce Bulk API to extract data for that table/object.
- Stores the extracted data as a gzipped CSV file.
- Completion Notification:
- Upon successful extraction, creates a new message containing information about the extracted data, such as the file location and metadata.
- Sends this message to
store_in_s3_queue, indicating that the extraction job for that table/object is complete and triggering the next step.
- Subscription: Listens to
3. S3 Upload Module
- Function: Handles uploading of extracted data to S3.
- Process:
- Subscription: Listens to
store_in_s3_queue. - Task Execution:
- Retrieves a message with details about the extracted data file to upload.
- Uploads the gzipped CSV file to the specified location in the Amazon S3 bucket.
- Completion Notification:
- Upon successful upload, creates a new message containing information necessary for the Snowflake merge step, such as the S3 file path and any required credentials.
- Sends this message to
merge_into_snowflake_queue, indicating that the upload job for that table/object is complete and triggering the next step.
- Subscription: Listens to
4. Snowflake Merge Module
- Function: Performs the merge operation in Snowflake.
- Process:
- Subscription: Listens to
merge_into_snowflake_queue. - Task Execution:
- Retrieves a message with details about the data file in S3 to merge.
- Executes a “MERGE INTO” SQL statement on Snowflake to update or insert records based on the new data.
- Completion Notification:
- Optionally, upon completion, can log success or send a confirmation message to another queue or monitoring system.
- If an error occurs, can send a message to a dead-letter queue or retry mechanism.
- Subscription: Listens to
Workflow Summary
- Step 1: The Job Loader queues extraction tasks in
data_extraction_queuefor each table/object. - Step 2: The Data Extraction Module processes each task, extracts the data, and upon completion, sends a message to
store_in_s3_queueto trigger the upload step for that specific table/object. - Step 3: The S3 Upload Module uploads the data to S3 and, upon completion, sends a message to
merge_into_snowflake_queueto trigger the merge step. - Step 4: The Snowflake Merge Module performs the merge operation in Snowflake for the specific table/object.
A visual flowchart for the pipeline:
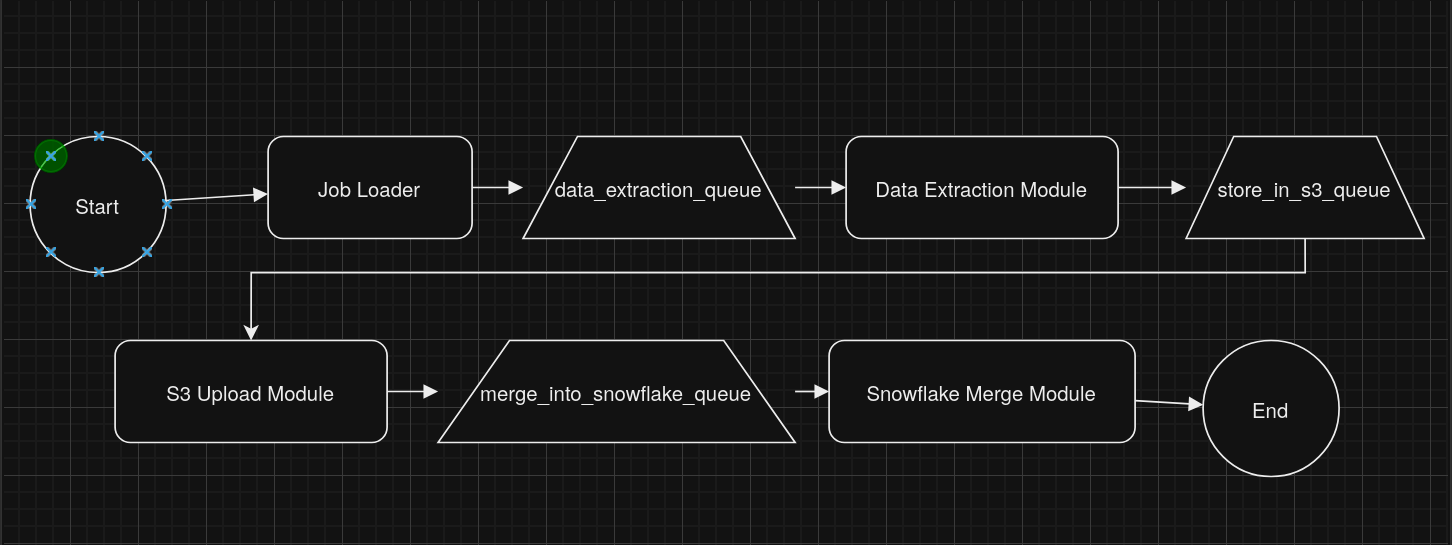
This design ensures that each step in the pipeline is decoupled and that the completion of one task explicitly triggers the next step for that particular table/object. It allows for fine-grained control and monitoring of each individual data processing task.
Important Features and Considerations
While message brokers offer significant advantages, it’s important to choose the right one and understand their features. Here are some key considerations:
Exactly-Once Delivery
One of the main features to look for is exactly-once delivery. This ensures that each message is processed only once, mitigating the risk of data duplication and reducing the complexity of your code.
- Why It Matters: In an ETL pipeline, processing the same data multiple times can lead to inconsistencies and incorrect results.
- How to Achieve It: Some message brokers provide exactly-once delivery guarantees, while others require idempotent consumers or additional mechanisms to prevent duplicate processing.
FIFO Ordering
Some use cases require FIFO (First-In, First-Out) ordering to maintain the sequence of message processing.
- Challenges:
- Implementing ordered processing in a distributed system is complex.
- It may limit asynchronous execution and scalability.
- Solutions:
- Use message brokers that support FIFO queues.
- Implement ordering logic in your application or at the database layer.
Language and Framework Compatibility
The choice of message broker may depend on the programming language you’re using.
- Considerations:
- Integration: Some languages have better support or client libraries for certain message brokers.
- Tooling: Availability of tools for monitoring and managing the message broker can vary.
Scalability Limits
Keep in mind that the pipeline’s horizontal scalability is now partially dependent on the message broker framework.
- Recommendations:
- Evaluate the performance characteristics of the message broker.
- Ensure it can handle your expected message volumes and throughput.
- Consider the ease of scaling the message broker itself.
Abstraction Layer
To prepare for potential changes, abstract the queue interface in your pipeline.
- Benefits:
- Flexibility to switch message brokers with minimal code changes.
- Easier maintenance and upgrades.
- Implementation:
- Create a wrapper or interface for queue operations (enqueue, dequeue, acknowledge).
- Use dependency injection or configuration to select the message broker implementation.
Conclusion
In this article, we’ve explored how using message brokers can simplify the creation of a stateless distributed ETL pipeline. By treating the message broker as a job server and structuring the pipeline into independent, stateless modules, you can achieve horizontal scalability and robustness.
Key Takeaways:
- Message Brokers Enable Scalability: They allow for smooth horizontal scaling without complex state management.
- Decoupled Modules Enhance Flexibility: Each module operates independently and communicates progress through messages, triggering the next step upon completion.
- Stateless Modules Simplify Scaling: Independent modules can be scaled up or down based on workload.
- Careful Selection Is Crucial: Choose a message broker with features that suit your needs, such as exactly-once delivery and compatibility with your programming language.
- Plan for the Future: Abstract interfaces and consider future expansion to ensure the longevity of your pipeline.
Message brokers have more utility than many realize, but they are not a silver bullet. Proper planning, research, and understanding of your specific use case are essential for building an effective and reliable data pipeline.